En el capítulo anterior hicimos un breve repaso por algunas de las herramientas de inteligencia artificial para generar imágenes que tenemos a nuestra disposición: Dall-E, Midjourney, Leonardo… Todas estas herramientas tienen algo en común: son propiedad de una empresa. Esto implica dos cosas: hay que pagar por su uso y sus características, funcionamiento y entrenamiento no depende de los usuarios.
Frente a esto, existe Stable Diffusion. Este modelo de IA también ha sido desarrollado por una empresa, Stability.ai, pero esta compañía ha optado por liberar todo el código del modelo bajo una licencia open source. ¿Qué significa esto?
- Es un modelo que se puede descargar, modificar y usar libremente por cualquier persona o entidad, sin restricciones de licencia o derechos de autor.
- Es un modelo que se basa en un conjunto de datos público (LAION5-B) con más de 5.000 millones de pares de imágenes-texto y que permite generar imágenes para cualquier tipo de texto o imagen.
- Es un modelo que se beneficia de la colaboración y el feedback de la comunidad de desarrolladores e investigadores, que contribuyen a mejorar su rendimiento y su calidad.
Las ventajas de trabajar con un modelo open source instalado en nuestro ordenador son evidentes: podemos crear tantas imágenes como queramos sin tener que pagar ninguna suscripción, y las imágenes generadas son exclusivamente nuestras. Como contrapartida, estos modelos precisan de una capacidad de computación muy alta, por lo que no todos los equipos están preparados para poder hacerlos funcionar.
¿Cómo crea Stable Diffusion las imágenes?
La comprensión profunda del funcionamiento interno de los modelos de difusión latente es algo que escapa al alcance de esta serie de artículos, pero con la ayuda de ChatGPT podemos entenderlo con la siguiente explicación simplificada:
- Entrenamiento: el modelo se entrena con un gran conjunto de imágenes y sus correspondientes descripciones para aprender la relación entre lenguaje e imágenes.
- Proceso de difusión: durante la generación, el modelo comienza con un patrón de ruido aleatorio y lo transforma gradualmente en una imagen, paso a paso, siguiendo las instrucciones textuales.
- Optimización: en cada paso el modelo ajusta la imagen para que se alinee mejor con la descripción dada, utilizando lo que ha aprendido durante el entrenamiento.
- Resultado final: después de varios pasos de ajuste y optimización, el modelo produce una imagen que coincide con la descripción textual proporcionada.
Este proceso permite crear imágenes nuevas que son coherentes con las entradas textuales y que capturan los detalles y el estilo descritos.
La comunidad de desarrolladores no ha tardado en crear sus propios modelos de IA generativa entrenados para fines específicos.
Stability.ai ha publicado hasta el momento varias versiones de su modelo de IA, siendo los más populares los denominados SD1.5 y SDXL, y ya está anunciada la versión SD3. Pero dado que Stable Diffusion es open source, la comunidad de desarrolladores no ha tardado en crear sus propios modelos entrenados para fines específicos, como Realistic Vision, entrenado para generar imágenes hiperrealistas, o DreamShaper, entrenado para crear ilustraciones de corte fantástico.
Interfaces gráficas para hablar con la máquina
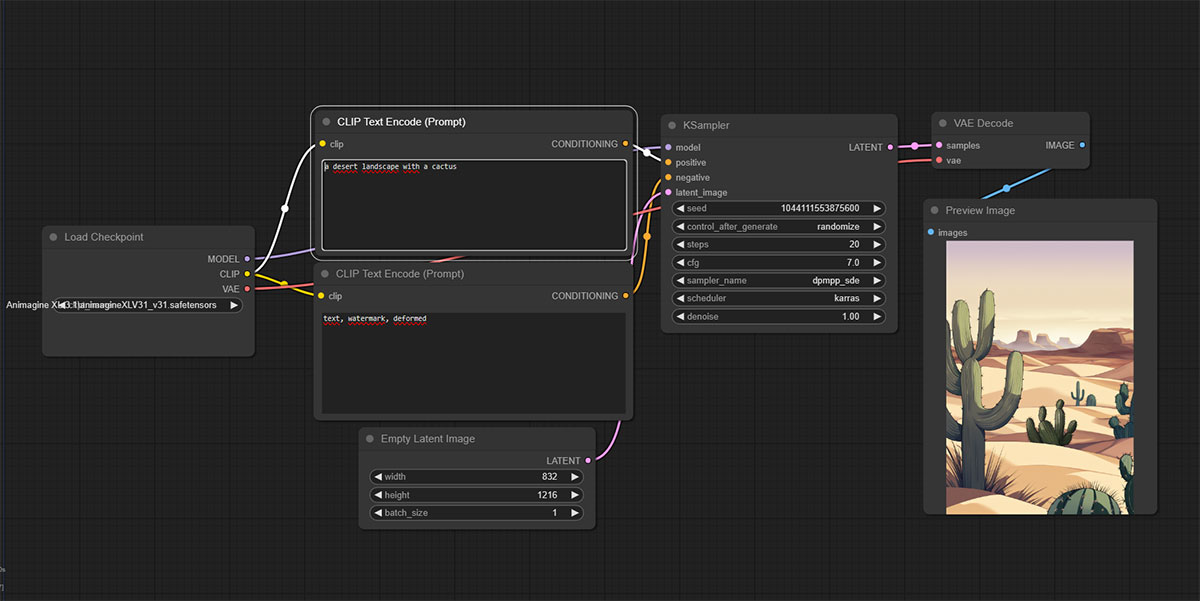
Además, también se han creado interfaces gráficas (web UI) que permiten trabajar con los modelos y generar imágenes sin necesidad de conocer el código específico para “hablar con la máquina”. Las dos interfaces más populares son Automatic1111 y ComfyUI.
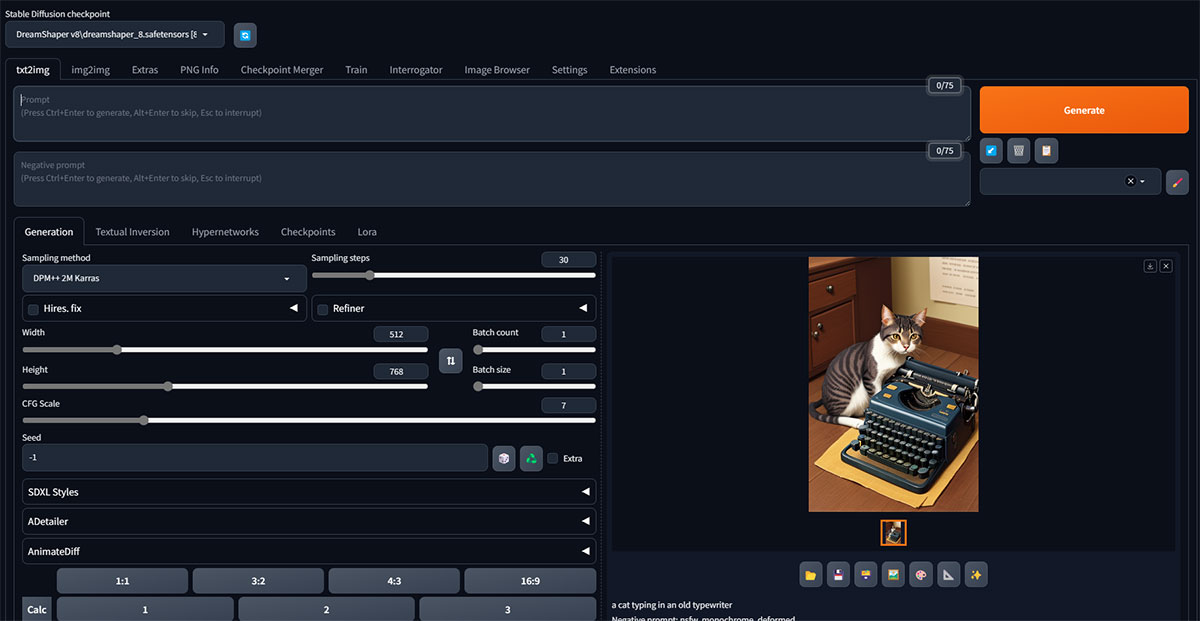
Una vez instaladas, ambas se ejecutan en el propio navegador del usuario y permiten ajustar los parámetros de generación. Entre sus opciones cuentan con herramientas muy avanzadas como outpainting e inpainting o soporte para modelos LoRa (pequeñas redes neuronales que se entrenan usando conjuntos de datos de imágenes para especializar un modelo en generar detalles específicos).
La interfaz de Automatic1111 destaca por su facilidad de uso, sobre todo en tareas avanzadas como el inpainting, que consiste en sustituir partes de una imagen por otras generadas mediante IA. Por su parte ComfyUI tiene una interfaz basada en un sistema modular, lo que la hace más compleja de utilizar pero también mucho más flexible y por tanto permite obtener resultados mucho más detallados.
Una vez vistas las herramientas con las que podemos trabajar, en el próximo capítulo nos centraremos en cómo escribir un buen prompt para que la IA genere esa imagen que tenemos en nuestra cabeza.
